
Crew
Fri Mar 04 2022
Today I released a new open source task management tool called Crew : https://github.com/orchard-insights/crew
At Orchard (formerly Dose) I struggled for a long time to effectively manage all the difficulties of building large ad campaigns with the Facebook Marketing API.
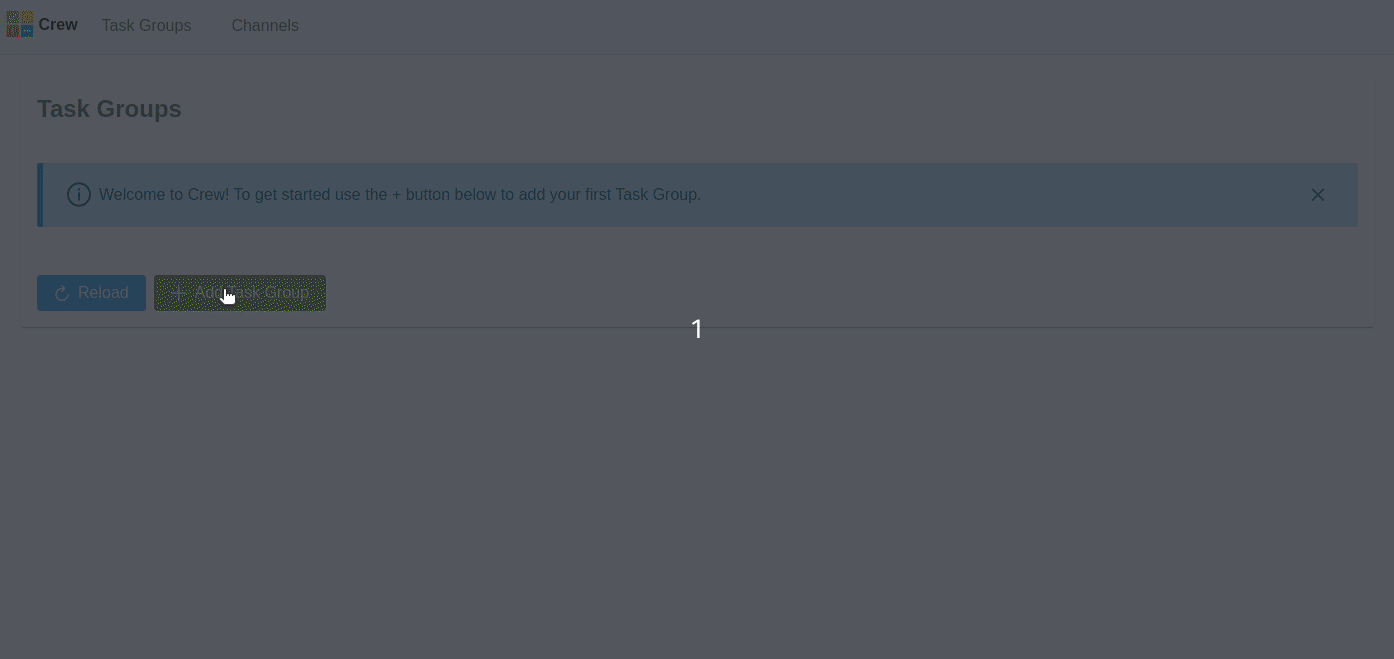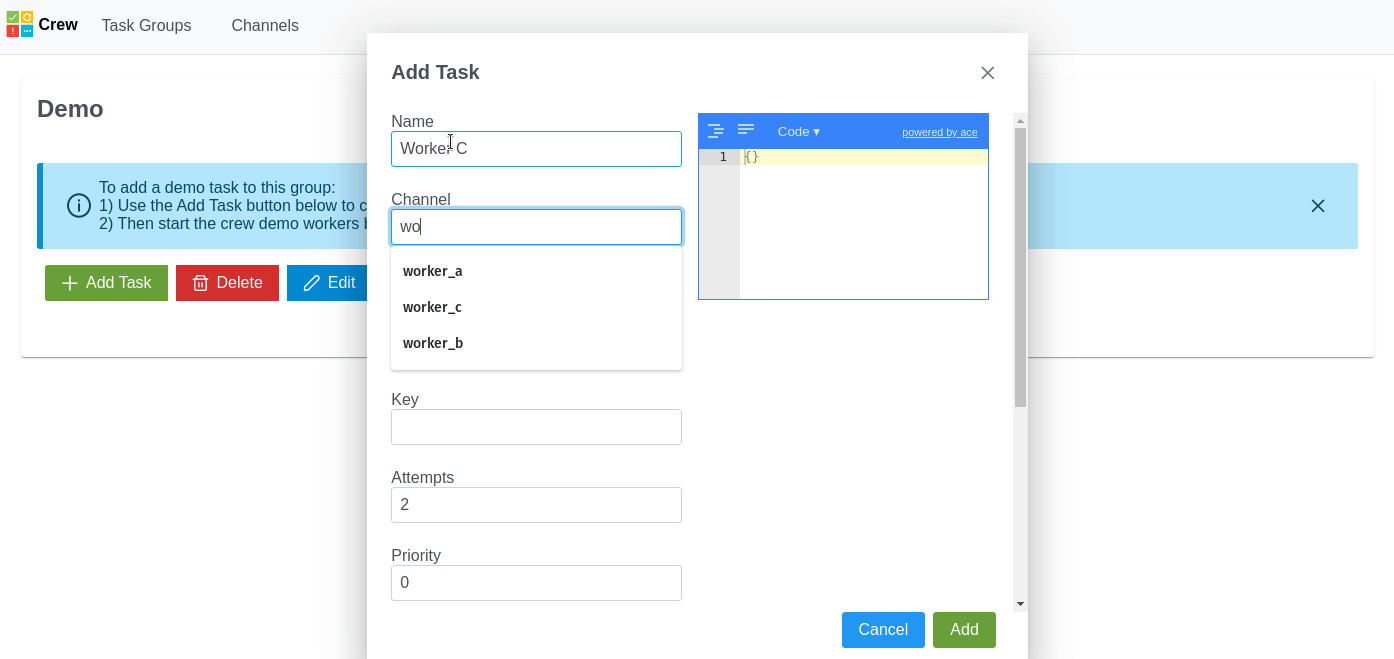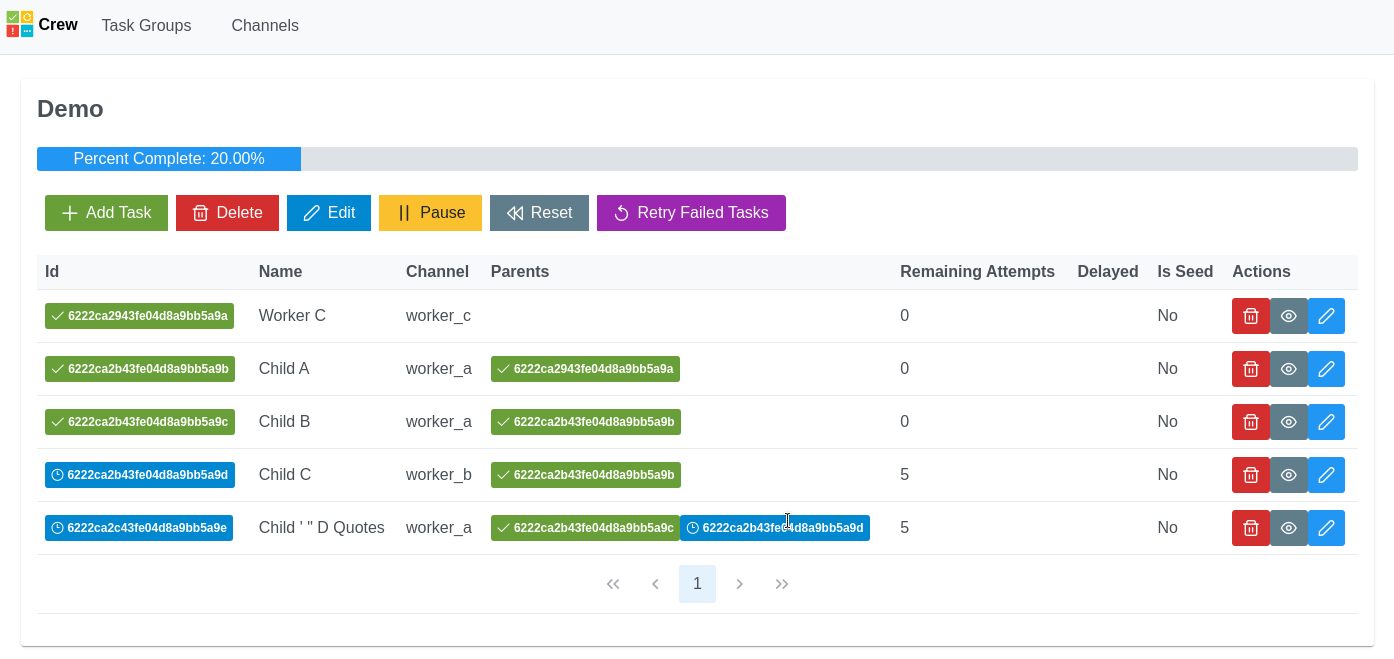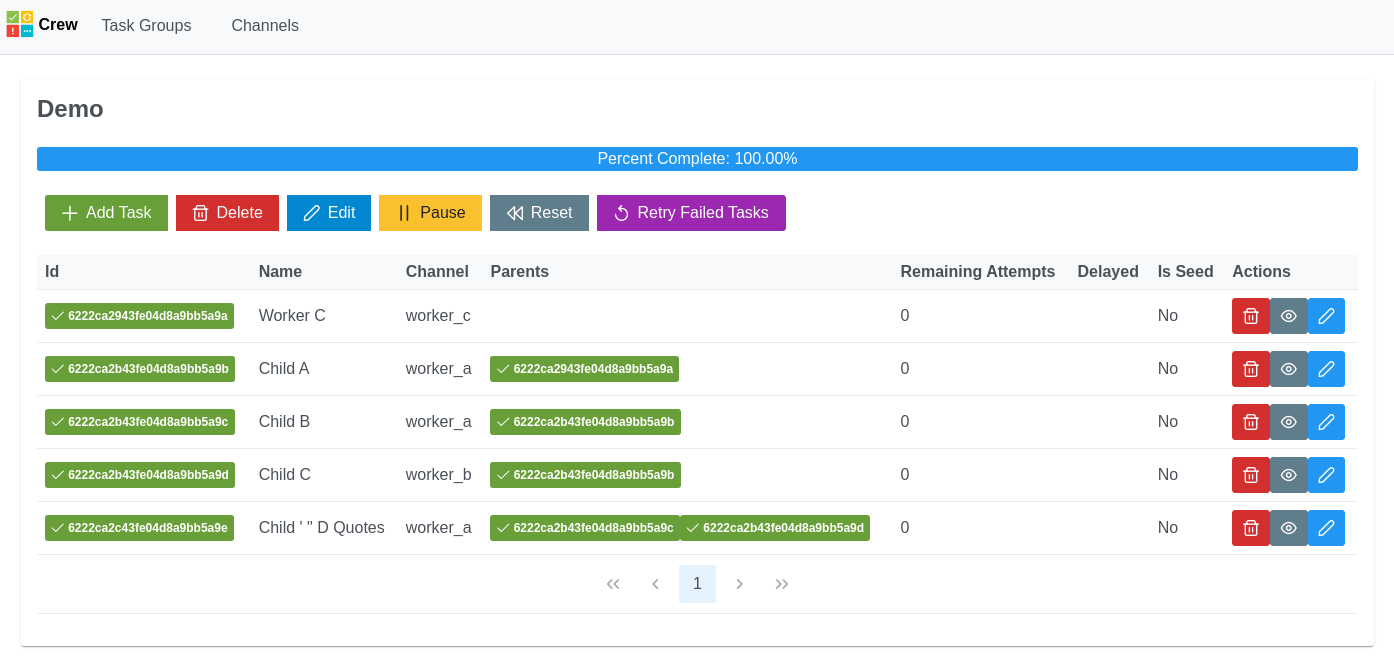
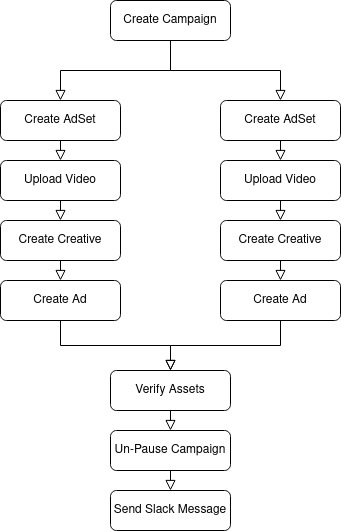
A critical problem is how to manage the complex chain of events that have to take place. First you need to create a parent ad campaign. If you're successful creating a campaign you can create its children adsets. This parent child structure is repeated down to the ad level. At each level, the work of building the entire ad campaign can only proceed if the parent objects are created successfully. Once the tree of campaigns, adsets, and ads are all finished, the workflow needs to be joined back together to perform QA checks and then notify stakeholders via Slack that the build is done. This results in a directed acyclic graph of tasks.
Unfortunately Facebook's API is by far the least reliable piece of technology I have ever worked with. I don't know if this happens to everyone but we get A LOT of totally random errors from Facebook. Therefore, as our tools work to build an ad campaign they have to be very fault tolerant and re-try API calls that have failed.
Then there are rate limits. Once your application runs out of API calls it has to pause all activity in order to "cool off". It needs to do this in a way that allows unaffected API tokens or apps to continue working.
For a long time I tried to do this with a modified version of BullMQ and was somewhat successful but kept having to babysit the system.
After extensive searches I was unable to find a tool that met all our needs:
- directed acyclic graph (DAG) structure of tasks
- tasks can create more tasks within the DAG (continuations)
- tasks can re-try upon error
- tasks can be scheduled or delayed
- groups of tasks that are impacted by a rate limit error can all suspended together
- duplicate tasks are not repeated
- workers can be written in JavaScript and Python
It was time to roll up my sleeves and make something from scratch. A first version of Crew was developed using Postgres and Hasura. It used the "FOR UPDATE SKIP LOCKED" feature in PostGRES to atomically assign tasks. It allowed task "workers" to subscribe to a stream of tasks via a GraphQL subscription. This worked really well for a long time and processed millions of jobs for Orchard.
Then we moved several of our services including Crew to render.com. We immediately encountered constant networking issues. In render.com our worker services were unable to maintain an open websocket connection to the Crew service for more than a few hours at a time. Because of the constant churn in the system due to lost connections I also kept running into issues with Postgres freezing up. I may have been improperly using SKIP LOCKED, but was unable to find a root cause. Everything ran fine on our previous host.
I thought about what to do for quite some time. I could have simply moved back to Kubernetes on our old cloud provider. However, what good is a task processing system if it can't run in "bad weather"?
For version 2 of Crew I decided to be very disciplined about keeping the tool as small and simple as possible. I decided to use MongoDB so I could leverage findOneAndUpdate. I also decided to opt for a simple express REST API. Although slightly slower for detecting new tasks, polling a REST API has proven much more reliable in an unreliable network. (Socket.io is included for workers that need to be informed of new tasks with low latency.)
We have been using this new version of Crew for over 6 months. In those six months it has distributed millions of tasks with zero downtime. It has been a crucial piece of technology for Orchard so we wanted to share it with everyone! Check it out here : https://github.com/orchard-insights/crew.